

康奈尔大学的研究人员开发了一种新的方法,使用低成本的立体摄像机,使自动驾驶车辆能够检测3D物体,其范围和精度接近激光雷达。
康奈尔大学的一组研究人员发表了一份研究报告演示新方法的论文目标检测显示出显著降低自动驾驶车辆硬件成本的潜力。他们通过显著提高光学摄像机用于三维物体检测的效率来实现这一点。在本文中,作者提出了他们的方法可以降低成本和/或提高自动驾驶车辆的安全性。
LIDAR数据和CNNS
近年来,很明显,自驾驶车辆将成为未来道路的常见景象。通过深度学习硬件和软件的进步,特别是将卷积神经网络(CNNS)应用于对象识别的应用,这是可能的大部分实现的,这允许自动车辆检测附近的行人,骑自行车者和其他车辆。到目前为止最成功的平台,例如由Waymo部署的平台,依赖于昂贵的光检测和测距传感器(LIDAR)来提供这些算法的输入。
相机输出为激光雷达数据
与激光雷达传感器相比,安装在车辆上的光学摄像头要便宜得多。已经有许多人尝试将摄像机用作目标检测的补充、备份或替换系统,但迄今为止,基于摄像机的系统显示出不足以实现这些功能的检测精度。
传统的基于摄像头的目标检测方法分析图像时,就像通过摄像头的镜头观看一样。该方法考虑了每个像素的颜色以及每个像素与相机的估计距离。本文的作者克服了光学相机的局限性,将相机输出视为基本上是激光雷达数据。
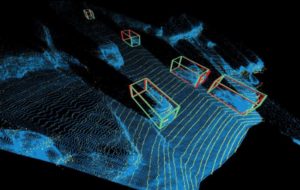
康奈尔研究人员证明的方法认为空间是类似于LIDAR数据的3D点云。
由于传统方法已经涉及从相机估计每个像素的距离,因此它们简单地,但非常敏锐地,在尝试对象检测之前将这些深度转换为3D点云。鉴于相机生成的点云之间的相似性和LIDAR传感器产生的相似性,研究人员能够使用3D视觉表示的基于深度学习的对象检测,就像它们一样,实际上是LIDAR数据。

给定立体或单目图像,预测深度图,然后将其反向投影到激光雷达坐标系中的三维点云中。
与传统的基于摄像头的方法相比,有了显著的改进
康奈尔大学研究人员的方法得分明显高于其他基于摄像头的方法基蒂基准。对基准度量的详细审查超出了本文的范围。通常,他们的“平均精度”(AP)得分是任何给定KITTI场景中其他基于相机的方法得分的两倍。它的得分范围从使用激光雷达产生的分数的25%到100%,这取决于应用的目标检测算法和使用的特定KITTI场景。
这些结果是对以前的基于相机的物体检测方法的显着改进,但它们仍然是独立指导道路上的自动驾驶车辆所需的东西。本文呈现的方法仍然很重要,因为它表明相机作为传感器的有效性并不是其产生的数据类型的不可挽回的限制。通过更改其输出如何表示对象检测算法,他们的AP得分可以并将在不久的将来增加。
反响
对基于相机的物体检测中预期的发展的影响可能导致自动车辆的几个创新。这些可能性最具破坏性的是显着降低自主车辆的成本。相机是比LIDAR传感器便宜的数量级。在扩大自动车辆市场的同时,肯定会转动最大的头部,但它还需要对康奈尔研究中概述的基于比较的基于相机的物体检测方法进行最大的增强。
组合点云等
一个更容易实现的里程碑是以某种方式将相机生成的点云和激光雷达生成的点云合并到同一个目标检测管道中。相机具有相对较高的空间分辨率,而激光雷达具有相对较高的精度。从这个意义上讲,这两个系统可以相互补充,以比目前单独使用激光雷达更高的精度检测物体。
最后,改进的基于相机的物体检测可以提供备份对象检测系统,用于当基于激光雷达的系统发生故障或以某种方式蒙蔽或类似的东西。这将使自动车辆更加可靠,在不同的情况下更可靠。
提交:汽车那机器人报告




告诉我们你的想法!