

David Stratman和Vinay Patwardhan,Cadence
在当今SOC的更复杂的世界中,您将大量的第三方IP块与您自己的高度调谐RTL集成在一起,同时在面对较低的电力需求和区域预算时积极推动频率。您还需要确保可靠的交接到放置和路线(P&R)。在本文中,我们将讨论可以通过以下方式来应对设计高级节点SOC的挑战的大规模平行RTL合成和物理合成技术和技术。
- Supporting early power, performance, and area (PPA) optimization of the datapath microarchitecture
- Correlating tightly to place and route
- 提高RTL设计生产力,以帮助您满足紧密的设计时间表
鉴于高端应用程序的复杂和大型SOC越来越多,巩固设计的微体系结构并尽早开始RTL合成比以往任何时候都重要。不仅如此,至关重要的是要开始该过程的权利,以确保对P&R的可靠切换以进行有效的设计关闭。否则,您会在P&R上面临浪费。
经过bringing physical considerations into the logic synthesis flow much earlier in the process, you can solve some of these challenges. Physical synthesis enhances the design process significantly and reduces the amount of time spent fixing problems late in the flow. However, current physical synthesis technologies have limitations when it comes to complex, advanced-node SoCs.
For complex SoCs, you need to be able to better model all critical physical effects related to placement, routing, and clocking. Such a process could be streamlined by using common engines and shared assumptions with the implementation technologies used later in the flow. Additionally, to handle growing SoC design sizes, you need techniques that can speed up synthesis runtime and capacity in order to be at your most productive level.
The Minimum Needed for Better Physical Synthesis
To build your physical synthesis foundation, you do need a few capabilities that are available today to help you generate a better netlist structure:
- 使用物理平面图进行RTL合成优化可以为P&R创建一个良好的初始网表,以支持更好的计时/电源/区域平衡
- The ability to structure your netlist to account for real wire delays and identify long wires allows synthesis to more effectively “squeeze” critical paths and “relax” non-critical paths, improving both correlation and timing
- 考虑物理范围的结构和映射技术可以帮助缓解路由拥塞和总负松弛(TNS)
- 物理综合可以帮助减少总芯片功率并优化设计(DFT)逻辑
What Can You Do to Enhance Your Synthesis Flow?
Limited capacity is one of the biggest hurdles for RTL synthesis of advanced-node SoCs. The massively parallel architecture trend has emerged as a viable solution. By tapping into a rapidly increasing number of processors in order to perform a set of coordinated functions concurrently, a massively parallel architecture can facilitate a much faster turnaround time, which results in improved RTL design productivity.
How the synthesis tool partitions the design, in concert with its massively parallel architecture, can also contribute to faster synthesis runtime. For example, imagine the productivity advantages if you could:
- 将您的设计分为流程中特定阶段的多个分区
- Run these partitions in parallel
- Merge the partitions back into the full chip
Taking this concept a step further, picture how much work you could get done if you could also break your entire design into multiple high-level partitions that are each taken through all stages of the design cycle.
当前的合成工具已经在许多地方都利用并行性,但是我们看到两个关键挑战限制了它们进一步扩展的能力而不会降低PPA:
- 长杆效应:The number of gates is not a good measure of optimization runtime. Different parts of a design may require different amounts of optimization effort to achieve a good result. If partitioning is based only on gate count and not optimization effort, then some partitions can become the “long pole” and bottleneck of any runtime improvements.
- Design hierarchy:The best partitioning to eliminate the long pole effect may not align with module or physical hierarchies, so partitioning needs to be able to “slice” through design hierarchy without forcing ungrouping of that hierarchy.
What is now needed to make partitioning effective is the assurance that you won’t experience the typical QoR or PPA degradation that can occur when recombining or merging the partitions back together.
Mapping capabilities are another area of consideration. Existing technologies do account for timing and area while doing synthesis, but independently and iteratively. What if you could look at your design globally and examine more than one constraint concurrently?
With smaller designs at established processes, it hasn’t always been important for synthesis to consider downstream effects like congestion. But downstream effects are certainly important with larger, advanced-node designs. If the mapping function in your synthesis tool could analyze different constraints concurrently and with an accurate physical context, then you’d be better able to produce a netlist that holds up through P&R.
下一代合成工具
The new Cadence Genus Synthesis Solution, a next-generation RTL synthesis and physical synthesis tool, overcomes limitations of traditional synthesis tools with innovative algorithms that improve RTL designer productivity. Its scalable, massively parallel global analytical architecture accelerates turnaround time. Its global datapath optimization engine can greatly reduce datapath area and power consumption. The solution provides:
- 最多可扩展5倍的合成时间运行时可扩展到10m+实例
- Ultra-tight correlation to P&R through shared engines and algorithms
- Global analytical architecture-level early PPA optimization, with up to 20% reduction in datapath area and power
- 从新的物理意识到的上下文产生能力中,单位和芯片级合成之间的迭代次数减少2倍+
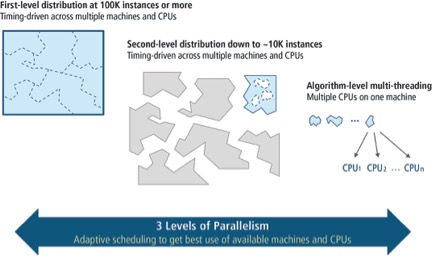
尽管使用大型高级节点的设计需要手动设计分区,但该方法是耗尽生产力和工程资源的方法。采用新的大规模并行RTL合成和物理合成技术可以增强您的合成流。下一代RTL合成和物理合成功能可以帮助确保即使是最小的单元级电路完全满足时间和电源目标,而最大的SOC块可以快速,准确地合成,以生成更好的相关网列和更快的最终磁带。
Cadence,Inc。
www.cadence.com
帖子Techniques to speed up SoC RTL and physical synthesisappeared first onAnalog IC Tips.
![]()
Filed Under:Analog IC Tips



