

当今跨行业部署的工业机器人大多执行重复任务总体任务性能取决于控制器跟踪预定义轨迹的精度机器人处理非构造复杂环境的能力在当今制造中有限
举两个例子灵活选择以前没有遇到对象或装配任务插入新部件多例壮观机器人演示显示灵敏度和高级控制,例如机器人Fanta挑战或机器人打乒乓但这些应用很难编程维护 通常是博士论文的输出 他们没有跳进制造
增强智能机自主获取技能是可取的主要的难题是设计可适应性强控制算法 面对建模所有可能的系统行为 和行为泛化必要性的固有困难
强化学习方法有希望解决这类挑战,因为它们使代理商能够通过与周围环境交互学习行为,并最理想地泛化新的不可见场景
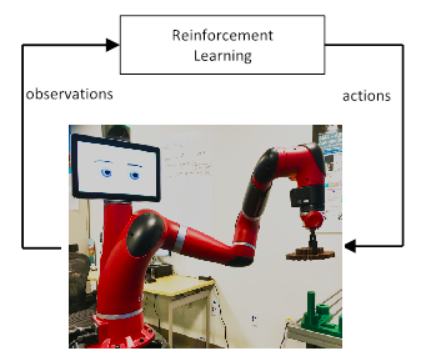
增强学习回路机器人控制西门子
强化学习
RL原则框架允许代理商通过环境交互学习行为相对于传统机器人控制方法,RL核心思想是向机器人控制器提供高层次规范,说明应做什么而不是如何做代理环境交互并收集观察和奖赏
RL算法强化高回报策略见Fig开工RL基于值函数方法与策略搜索在政策搜索中,机器人学习从状态到动作的直接映射以值函数为基础的方法中,机器人学习值函数,中间结构评估显性状态值并从值函数中产生动作
政策搜索和基于值函数方法都可基于模型或免模式无模型方法不考虑世界动态模型方法结合世界动态模型,从数据中学习
强化工业应用学习
可以看到,机器人控制方法可分组成连续体,一端我们发现“ripid”反馈控制法则,这些法则由人工设计,集域知识并用数据调节控制结构光谱的另一端我们有RL方法,允许学习控制策略完全取自观察数据两种方法都有利弊
传统反馈控制方法可高效解决各类机器人控制问题,例如自由空间轨迹跟踪,通过清晰模型捕捉结构,如硬体运动方程现代制造中许多控制问题处理接触和摩擦问题,难以用一阶物理建模捕捉高层次推理需求(例如选择垃圾桶问题)当前机器人控制器缺乏弹性应用反馈控制设计方法处理这类问题往往导致易失精密控制器,这些控制器必须人工调适部署
反之,RL原则上可以学习控制结构然而,对实战机器人而言,持续探索空间很大,因此需要大量数据并因此需要较长培训时间。与传统反馈控制不同,聚合和稳定性报表很难产生RL方法
点最近常用两种控制方法的两个案例波士顿动态以部署常规反馈控制法(更确切地说,漏网控制法)Google则显示RL能找到机器人控制器,数月机器人农场培训实现所需控制性能
发现机器人控制方法由连续式组成后, 底层维度是在线数据对控制算法影响多深后, 弹性制造最佳控制性能似乎必须同时结合传统控制理论和数据驱动RL传统控制可提供安全性能保障,而RL可带来灵活性和适配性,如果调适正确以某种方式,RL去除工程阶段所需的特性,即控件设计目标实现与仔细设计反馈控制算法相同的性能,但不需要烦琐编程和规则
由感知、状态估计、控制等组成分题分解机器人控制管道,用传统方法和子题可明确解决,用RL处理最终控制策略从一阶模型中并发数据驱动组件和控制策略方法综合传统控制理论的好处(例如数据效率)灵活RL位置控制由pID控制器处理,RL提供控制部分处理摩擦和接触对不同工业相关使用案例进行了研究,其中包括机器人执行实战装配任务,包括联系人和不稳定组件
图2显示两种组合使用案例,即常规反馈控制与RL合并以灵活方式解决复杂汇编任务子图(a)和(b)显示轮子如何安装轴用例西门子机器人学习挑战机器人需要小于7迭代学习所需控制策略子图(c)和(d)显示不同的使用案例,并使用与a和b相同的控制算法重复,小于7迭代后,机器人学习控制策略

图2 插入使用案例通过组合常规控制加固学习解决西门子
方法上挑战持续存在七次迭代似乎合情合理 实验搭建, 但它们隐含风险, 因为在多摩擦环境的每一次迭代都有可能 破坏部分接触抓柄精确传感器和适当的约束管理可缓解问题管道使用传统控件处理得更好,并可以滤出RL命令输出注意还需要一定量工程来确保机器人不处于锁位,因约束而无法移动遇上这些情境 呼人求援可能是最佳行动路线.此外,为减少真实世界迭代数,模拟现实差新法(im2real)证明加速学习.
根據机器人应用的强化学习流传 并有有效动机但它不是保证成功的主要成份端对端学习方法显示任务性能差需要精度类比中,我们喜欢做, 如果你想做巧克力蛋糕, 朱古力(增强学习本例)不是主成份鸡蛋面粉等非性化成份在我们例中是传统控制方法它们是构建成功柔性机器人应用的基础
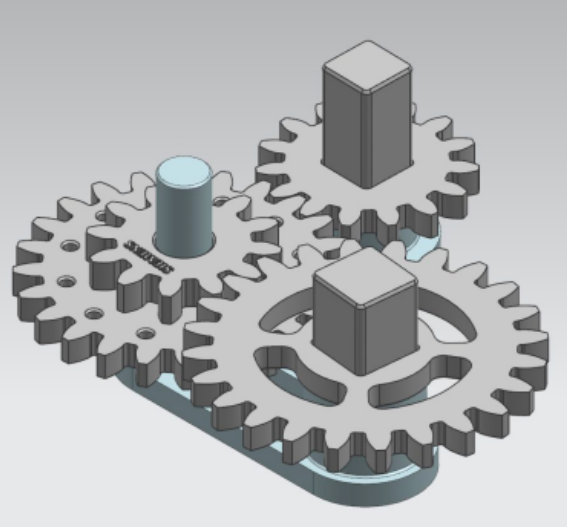
图3 西门子机器人学习挑战西门子
机器人学习挑战
我们强烈认为,加速机器人学习研究及其产业适配需要研究界基准图像网基准由飞飞Li于2009年推出,机器分类性能2015年超人能力基准加速研究,因为它们便于复制并允许比较研究
机器人采摘这项工作向右走机器人汇编方面仍然需要全球接受基准。因此,我们在2017年首届机器人学习大会上引入Siemens机器人学习挑战挑战由fig显示的齿轮装配任务组成2(a)和(b)及Fig3级细节和三维打印模式可在此获取
自挑战启动以来,我们看到各种研究工作正在发布,以西门子机器人学习挑战为基础-见实例来并来.我们愿鼓励社区尝试挑战并帮助我们完善它以覆盖尽可能多的案例机器人学习社区只能用常见易复制基准开始搭建管道和工具并想提供结果, 自由发电子邮件给作者

阿帕里西奥
关于作者
Juan AparicioCA西门子公司技术高级制造自动化主管Aparicio管理复杂项目经验丰富 硬件软件并消除大学与企业之间的技术空白兴趣领域包括高级制造、先进机器人、连通汽车、工业4.0和网络物理系统
Aparicio是美国高级制造机器人学院技术咨询委员会成员以及开放进程自动化论坛项目管理员

柔珠
博士欧根Sowjow研究科学家 精通机器人和机器智能 西门子公司技术获汉堡理工大学博士学位从2012年到2017年,他受雇TUHH和UC访问研究员伯克利
欧根技术牵头多政府资助项目TUHH并获多项奖学金、研究金和学术奖项
文件基础:机器人报表,机器人抓包器




告诉我们你的想法