

大卫·莱特曼(David Letterman)所说的“愚蠢的机器人把戏”(Stupid Robot Tricks)可能即将落幕,因为智能机器开始在各种各样的体力和智力追求上超越人类。2016年3月,谷歌旗下的DeepMind软件程序AlphaGo击败了当时的围棋冠军李世石。围棋是一种起源于3000多年前的中国游戏,据说比国际象棋复杂多了。李宗伟曾获得18个世界冠军,被认为是过去10年里最伟大的选手。如今,AlphaGo拥有世界排名冠军。
解析DeepMind团队如何能够跨越计算机科学家一度无法逾越的门槛,可以为了解机器人专家可用的工具提供入门知识。根据AlphaGo官网,传统的人工智能方法在所有可能的位置上构建搜索树,在围棋中没有机会。这是因为可能的走法太多了,而且很难评估每个可能的棋盘位置的力度。”
相反,研究人员将传统的搜索树方法与深度学习系统相结合。“一个神经网络,即‘政策网络’,会选择下一步的行动。另一个神经网络是‘价值网络’,它预测游戏的赢家。”然而,AlphaGo的关键是让人工智能通过严格的“强化学习”方法,从游戏数据库中与自己下棋数千次。
“我们向AlphaGo展示了大量强大的业余棋局,以帮助它发展自己对人类合理棋局的理解。然后我们让它与不同版本的自己玩了数千次,每次都从错误中学习,并逐步改进,直到它变得非常强大。”
到2017年10月,人工智能变得非常强大,它绕过了包含人类输入的专业和业余游戏的强化学习过程,只玩自己的早期版本。新程序AlphaGo Zero以100比0击败了几个月前击败世石的前一个程序,使其成为历史上最伟大的围棋棋手。Deep Mind现在希望将这种逻辑应用到“与围棋等游戏具有相似属性的大量结构化问题上,比如计划任务或需要按照正确顺序采取一系列行动的问题。例如蛋白质折叠、降低能源消耗或寻找革命性的新材料。”
强化身体技能的学习
强化学习技术并不局限于策略游戏。加州大学伯克利分校人工智能研究(BAIR)实验室的研究人员最近展示了一项用YouTube视频来训练人形人模仿动作。利用与AlphaGo类似的方法,BAIR团队开发了一个深度学习神经网络,该网络将在线看到的演员的动作近似为机器人的编程步骤。BAIR团队在其博客中写道:“每分钟有300小时的视频被上传到YouTube,令人震惊。”“不幸的是,对我们的机器来说,从这么大量的视觉数据中学习技能仍然是非常具有挑战性的。”
为了访问这些训练数据的宝库,今天的程序员被迫购买和运送笨重的动作捕捉(mocap)设备来创建自己的演示视频。BAIR的研究人员薛斌(Jason) Peng和Angjoo Kanazawa说:“动作捕捉系统也往往局限于有最小遮挡的室内环境,这可能会限制可以记录的技能类型。”为了应对这一挑战,彭和金泽着手创建一个无缝的AI平台,让无人系统通过解压缩数小时的在线视频剪辑来学习技能。
论文指出:“在这项研究中,我们提出了一个从视频(SFV)中学习技能的框架。通过结合最先进的计算机视觉和强化学习技术,我们的系统使模拟角色能够从视频剪辑中学习各种各样的技能。给定一个演员表演某些技能的单目视频,如侧手翻或后空翻,我们的角色能够学习在物理模拟中重现该技能的策略,而不需要任何手动姿势标注。”
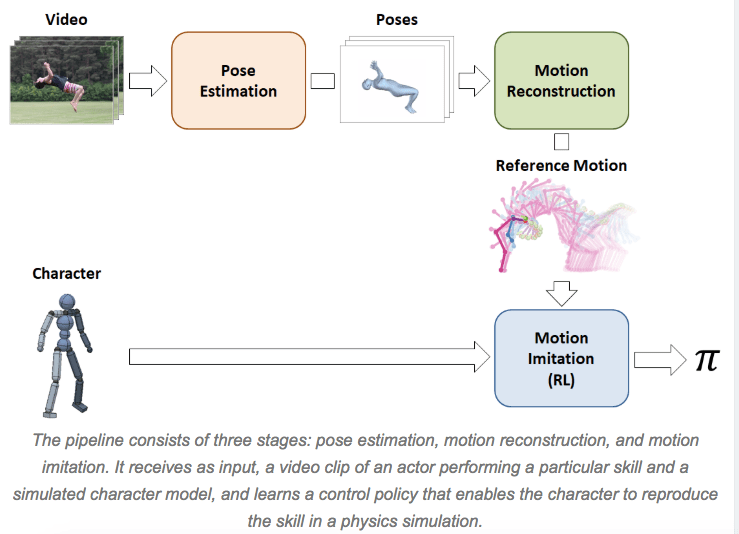
未来的发展
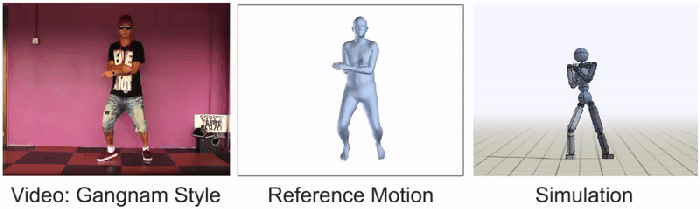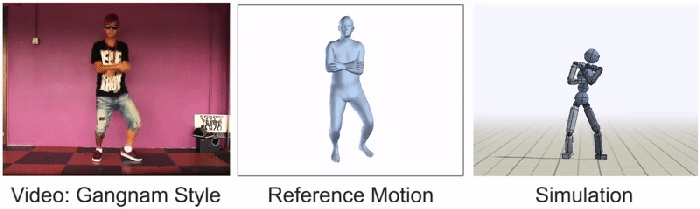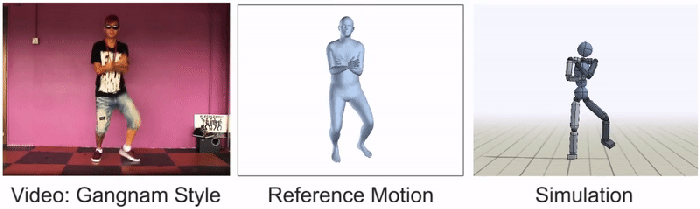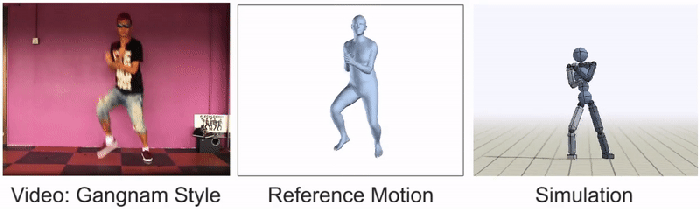
视频通过一个代理传送,该代理将动作分解为三个阶段:“姿势估计、动作重建和动作模仿。”第一阶段预测主体初始姿势后的帧。然后,“运动重建”将这些预测重组为“参考运动”。最后一个过程是用动画角色模拟数据,这些动画角色通过强化学习继续训练。SFV平台实际上是Peng和Kanazawa早期使用动作捕捉视频的系统DeepMimic的升级版。到目前为止,通过普通在线视频获得的20种不同技能的结果令人震惊,如下图所示:
Peng和Kanazawa希望未来可以利用这种模拟使机器在新环境中导航:“即使环境与原始视频中的环境非常不同,学习算法仍然开发出相当合理的策略来处理这些新环境。”该团队也对其对推动移动无人系统发展的贡献表示乐观,“总而言之,我们的框架真的只是采用了任何人在解决视频模仿问题时能想到的最明显的方法。关键在于将问题分解为更易于管理的组件,为这些组件选择正确的方法,并将它们有效地集成在一起。”
BAIR团队谦虚地承认,大多数YouTube视频仍然过于复杂,他们的人工智能无法模仿。奇怪的是,彭于晏和金泽把《江南style》作为其中一个障碍。“我们还有很多工作要做,”研究人员宣称,“我们希望这项工作将有助于激发未来的技术,使特工能够利用大量公开的视频数据,获得一系列真正惊人的技能。”
了下:机器人报告,机器人•机械手•末端执行器




告诉我们你的想法!