

了解对象的3D位置和方向,通常称为6-DOF姿势,是机器人能够操纵每次不在同一位置的对象的关键组件。NVIDIA研究人员开发了一个深入学习系统,培训了合成数据,可以使用一个RGB相机。
NVIDIA表示,它的深度对象姿态估计(涂料)系统在瑞士苏黎世的机器人学习(Corl)会议上介绍,是让机器人在复杂环境中有效工作的另一步。阅读论文“家庭对象语义机器人掌握的深度对象姿态“更深入的细节。
NVIDIA的主要研究科学家Stan Birchfield告诉机器人报告通过NVIDIA的算法和一张图像,机器人可以推断出物体的3D姿态,以便抓取和操作它。与真实数据相比,合成数据的优势在于,它可以为深度神经网络生成几乎无限数量的标记训练数据。
“真实的数据需要手工标注。对于一个非专业人士来说,给这些图片贴上标签是非常困难的。“我们研究如何用合成数据训练网络已经有一段时间了。”
NVIDIA表示,合成数据的关键挑战之一是弥合“现实差距”的能力,使得在合成数据上培训的网络与现实世界数据正确运行。NVIDIA表示,它的一击深神经网络尽管有限的基础,已经实现了这一点。使用NVIDIA TESLA V100 GPU在DGX站上,通过CUDNN加速的Pytorch深度学习框架,研究人员培训了由由NVIDIA开发的自定义插件产生的综合数据进行深深的神经网络,这对于其他研究人员公开可用。
“具体来说,我们使用非光电域域随机化(DR)数据和光电环境数据的组合来利用两者的优势,”NVIDIA研究人员在纸上写道。“这两种类型的数据彼此相互补充,产生了比单独所实现的结果要好得多。合成数据具有额外的优点,因为它避免了对特定数据集分布的过度拟合,从而产生对照明变化,相机变化和背景的强大的网络。“
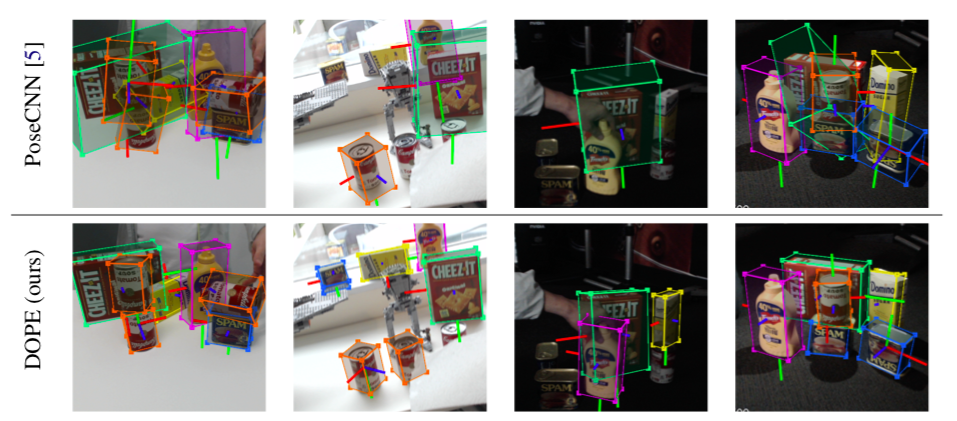
图3:YCB对象对显示极端照明条件的数据的姿态估计。TOP:POSECNN [5],它在YCB-Video DataSet的合成数据和实际数据的混合中培训,努力推广,以不同的相机,极端姿势,严重遮挡和极端照明遍布这一场景变化。底部:NVIDIA的涂料方法概括为这些极端的真实情况,即使它仅在合成数据上培训;除闭塞汤可以(第二栏)和三个暗罐(第3栏)外,还检测到所有物体。
测试NVIDIA的系统
该系统分两步接近其掌握。首先,深神经网络估计图像坐标系中所有对象的2D关节点的信仰图。接下来,将来自这些信仰图的峰值馈送到标准透视图-N点(PNP)算法以估计每个对象实例的6-DOF姿势。
要将其姿势估算系统置于测试中,NVIDIA将Logitech C960 RGB摄像头附加到来自Rethink机器人的Baxter双武装Cobot的腰部。使用Logitech相机和手腕相机可见标准棋盘目标,罗技摄像机被校准到机器人基础。根据安装的橡胶尖端的厚度,平行钳口夹具从大约10厘米至6厘米,或8cm到4cm的开口移动。
研究人员使用了五个物体,在杂乱中放置,在机器人前面的桌子上的四个不同位置,在每个位置的三种不同的方向上。被指示Baxter机器人移动到对象上方的预抓取点,然后执行自上而下的掌握,从而产生每个对象的12个试验。在那些12次尝试中,这里是每个物体的成功掌握的数量:10(饼干),10(肉),11(芥末),11(糖)和7(汤)。
NVIDIA表示,汤的圆形可以造成一些问题与自上而下的掌握。当研究人员重复躺在其旁边的汤罐的实验时,成功的掌握数量增加到12个尝试中的9个。
Rethink机器人10月3日关闭了门。这由于哈恩集团收购了IP。是一位德国自动化专家,将继续制造和销售Sawyer Cobot。我们向Birchfield询问了他对Baxter Robot的看法。
“作为一名研究人员,我们对百斗非常满意。它对价格具有大量的能力,“Birchfield说。“贝尔特不知道该公司出生了。但我们的机器人实验室拥有各种机器人,使我们能够测试不同的机器人前进。“
NVIDIA的后续步骤
在新闻时,Birchfield表示,该系统仅在这五个物体上培训。研究人员正在脱离众所周知的耶鲁 - CMU-Berkeley(YCB)对象和模型集,其中包括77个日常物品。Birchfield表示,系统可以检测的对象数量没有限制,但研究人员“采用了一个代表各种不同尺寸和形状的子集,这些尺寸和形状很容易访问商店并尝试。”
Birchfield表示,该系统将使其他机器人开发人员能够通过解决感知问题的关键部分来获得其项目的JumpStart。
“机器人学是一种多学科领域,即研究人员由于时间而在他们身上挑战,”Birchfield说。“常常具有感知,人们将使用AR标签来帮助解决该问题。无需使用AR标签,我们的技术将帮助他们越来越靠近现实世界。“
NVIDIA表示,下一步是增加可检测物体的数量,处理对称性并结合闭环细化以增加掌握成功。
提交:机器人报告




告诉我们你的想法!